



Weekly writing about how technology shapes humanity and vice versa. If you haven’t subscribed, join 50,000+ weekly readers by subscribing here:
Hey Everyone 👋 ,
It’s hard to focus on technology and business metrics during a week like this. My heart goes out to Israel. Some members of the tech community are making a tangible difference on the ground: Notion’s Ben Lang, for instance, is buying food for civilians and soldiers—DM him here to contribute.
LLMs for Dummies
Plus, 4 Frameworks for LLM Applications
Large language models have improved rapidly in recent years. To put their improvement in perspective, consider this analogy:
If air travel had improved at the same rate as LLMs, average flight speed would have improved from 600mph in 2018 to 900,000mph in 2020—a 1,500x increase in two years. Instead of taking eight hours to travel from London to New York, it would take just 19 seconds (!).
This is based on the number of parameters in GPT-1 vs. GPT-3. GPT-3 has 175 billion parameters, and GPT-4 is rumored to have many, many more (OpenAI hasn’t disclosed GPT-4’s parameters). This chart is dated, but it gives you a sense of model size in a short period:

Of course, air travel exists in the world of atoms, while LLMs exist in the world of bits. This is why LLMs can improve exponentially, thanks to Moore’s Law. But the example of air travel is helpful in illustrating the sheer magnitude of improvement we’ve seen the past few years. It’s difficult to wrap your head around.
We talk about LLMs a lot these days, but we talk less about how they work—their plumbing, what goes on behind the scenes. How does ChatGPT digest a prompt and spit out a coherent, well-written short story?
Answering that is the goal of this week’s piece. We’ll dig into a high-level exploration of how LLMs work, in layman’s terms—think: the ubiquitous “For Dummies” books from the 2000s—and then look at four frameworks for LLM applications that might emerge in the startup ecosystem.
LLMs for Dummies
Four Frameworks for LLM Applications

Let’s dive in 👇
LLMs for Dummies
The inner-workings of LLMs are complicated; even researchers don’t fully understand how the models work. But it’s helpful to have a basic understanding of what happens when you use ChatGPT. The two in-depth explainers I’ve found most helpful are this piece from Ars Technica and this piece from FT. I recommend reading these for detailed explainers, but my goal here is to share takeaways that offer an easy-to-grasp, high-level understanding of LLMs.
These are language models, so let’s start by talking about language:
Humans represent words with letters. C-A-T spells “cat.” Language models represent words with numbers. A lot of numbers. These are called word vectors, and here’s one way to represent “cat” as a vector:
[0.0074, 0.0030, -0.0105, 0.0742, 0.0765, -0.0011, 0.0265, 0.0106, 0.0191, 0.0038, -0.0468, -0.0212, 0.0091, 0.0030, -0.0563, -0.0396, -0.0998, -0.0796, …, 0.0002]
Words are complex, and language models store each specific word in “word space”—a plane with more dimensions than the human brain can envision. It helps me to picture a three-dimensional plane, to get a sense of how many different points exist within that plane. Now add a fourth, fifth, sixth dimension.

You can envision each word stored as a vector in this plane. Language models store words in “clusters,” with similar words placed closer together. For instance, the word vectors closest to cat include dog, kitten, and pet. Here are other examples of clusters:

The language model determines vector placement and clusters based on a neural network that’s been trained on heaps and heaps of language: the neural network gets really good at knowing that dog and cat often occur together, that walk and run are similar in meaning, or that “Trump” often follows “Donald.” It then clusters those words together.
Vectors act as good building blocks for language models because they can capture subtle, important information about the relationships between words. From Ars Technica:
If a language model learns something about a cat (for example, it sometimes goes to the vet), the same thing is likely to be true of a kitten or a dog. If a model learns something about the relationship between Paris and France (for example, they share a language), there’s a good chance that the same will be true for Berlin and Germany and for Rome and Italy.
A newly-created language model won’t be very good at this. It might struggle to finish the sentence, “I like my coffee with cream and…” But with more and more training, the model improves. Eventually, the model will become good at predicting “sugar” as the word that should finish the sentence. For humans, this comes intuitively; for language models, this happens with a lot of math in the background.
The key is scale. GPT-3 was trained on nearly the entire internet—books, articles, Wikipedia. The model was trained on about 500 billion words. By comparison, a human child has absorbed about 100 million words by age 10. So that’s a 5,000x multiple on the language digested by a 10-year-old.
(One downside of the training data: because large language models have been trained on human content, they inherit human biases. In word vector models, for instance, associations between “female” and “medicine” may be more likely to produce the noun “nurse,” while associations between “male” and “medicine” may produce the noun “doctor.” Researchers are working to mitigate human biases that have crept into AI.)
What’s complex about language is that it’s full of nuances. Computers were originally built for computation (hence the name), which is more straightforward: 2 + 2 always equals 4. But words can have many meanings. I like these examples from Ars Technica:
In “the customer asked the mechanic to fix his car,” does “his” refer to the customer or the mechanic?
In “the professor urged the student to do her homework” does “her” refer to the professor or the student?
In “fruit flies like a banana” is “flies” a verb (referring to fruit soaring across the sky) or a noun (referring to banana-loving insects)?
This is tough. The model needs to understand the context around each word. To use an example from the FT, “interest” in this sentence has two meanings:

In the first use, other words in the word cluster might include “enthusiasm” and “encouragement”; in the latter use, related words might include “profit” and “dividends.” How does the model know which meaning of “interest” is the intended one?
For that, we need to talk about transformer models.
A transformer is a type of architecture for the neural network. You can think of it as a series of layers. Each layer of the model synthesizes some data from the input, storing that data within new vectors (which are called a hidden state). Those new vectors are then passed to the next layer in the stack.
To vastly oversimplify, take a few examples for the sentence above:
➡️ The first layer of the stack might mark “I” and “bank” as nouns
➡️ The next layer of the stack might notice that “I” and “no” and “in” are all related to the first use of “interest,” thus recognizing that the word, in this sentence, means something close to enthusiasm
➡️ A third layer might then note that the second “interest” relates to “bank,” deducing that it is financial in nature (and that “bank” means a financial institution, not a river bank)
And so on.
Simply put, each layer of the transformer gets “smarter” and better at grasping the sentence’s meaning and nuances. Ars Technica notes that the first few layers tend to focus on understanding a sentence’s syntax and resolving any ambiguities (“interest” vs. “interest” for example). Then, later layers tackle a more holistic understanding of a passage’s meaning.
Of course, the real thing is much more complex. The most powerful version of GPT-3 has 96 layers. And, naturally, word vectors are much more complicated than we can show here. The most powerful version of GPT-3 uses word vectors with 12,288 numbers. (Again, things have improved fast: GPT-1, released in 2018, had 12 layers and 768 numbers in its word vectors.)
Those 12,288 numbers—called dimensions—become important for complex inputs.
As an LLM digests a long written work, it continues to adapt word vectors to add more and more information and context. If I’m the main character of the story, for instance, the model may shift the “Rex” vector in each layer of the transformer to contain more and more information: “(main character, lives in New York, from Arizona, venture capital investor at Daybreak, writes Digital Native, incredibly mediocre tennis player…)” You get the picture.
That’s the crux of how LLMs work—they translate words to (lots of) numbers, then adapt those numbers in each level of the stack to understand context and meaning.
What’s cool is how good these models have become at quite nuanced language concepts. Scientists at Redwood Research studied GPT-2 to see how it would finish the sentence, “When Mary and John went to the store, John gave a drink to ___.” The model was able to fill in the blank with “Mary,” and further investigation by researchers showed that the model had used a “Subject Inhibition” attention head to block John from being used again; put more simply, the model recognized that it wouldn’t make sense for John to give a drink to John, so it blocked him and looked for another potential subject in the sentence.
Of course, language is complex. If the sentence were, “John and Mary arrived at the restaurant, and John gave his keys to ____” the logical word wouldn’t be Mary, but “the valet.” Humans know this, but the valet isn’t mentioned anywhere in the sentence. Still, ChatGPT nails this challenge:

Not bad. The model likely uses “give”, “restaurant”, and “keys” as contextual clues to answer the question.
As a final example of how adept LLMs have become, consider this example from Stanford’s Michal Kosinski (my old professor!). Koskinski gave a language model this paragraph:

Most humans can guess that Sam will think the bag contains chocolate, and thus be surprised to discover popcorn inside. (In psychology, this is called “theory of mind”—defined as “the capacity to understand other people by ascribing mental states to them.”) An unsophisticated LLM might get theory-of-mind questions wrong, but more recent models pass with flying colors; from Ars Technica:
GPT-1 and GPT-2 flunked this test. But the first version of GPT-3, released in 2020, got it right almost 40 percent of the time—a level of performance Kosinski compares to a 3-year-old. The latest version of GPT-3, released last November, improved this to around 90 percent—on par with a 7-year-old. GPT-4 answered about 95 percent of theory-of-mind questions correctly.
LLMs are much more complex than this short summary lets on. The goal here was to capture a high-level understanding of how LLMs train on vast amounts of data, then perform a series of complex, rapid calculations to translate inputs into outputs. For more in-depth analysis, check out this piece from Timothy B. Lee and Sean Trott, this piece from Madhumita Murgia, or NVIDIA’s deep-dive into transformer models.
Let’s now look at what LLM applications might emerge…
Four Frameworks for LLM Applications
The other day, someone told me, “I finally found a use case for ChatGPT that Google Search couldn’t get.” He was trying to remember the name of a favorite blog. He asked Google, but got nothing. ChatGPT, though, got it right away:

(Great blog, by the way.)
Friends have been sharing other clever ways to use ChatGPT. This example from my friend Peter is a favorite:

Even though ChatGPT has taken off—and become the fastest-growing product in history—broader LLM applications are still early.
Last month, I wrote about how we’re in Phase One of a new technology revolution—a time of innovation, yes, but still early innings. The application layer has yet to truly emerge.

One comparison I drew in that piece was a comparison to mobile’s application ecosystem. The iPhone came out in June 2007; Uber was founded in March 2009. Killer apps take time.
Here’s a chart of U.S. smartphone ownership after the iPhone came out—I overlaid the foundings of WhatsApp (2009), Uber (2009), Instagram (2010), and Snap (2011).

LLMs are a powerful and new technology that can transform how we live and work. But we’re early days. Here are four frameworks I use for how LLMs might be applied:
1) Make Impossible Problems Possible
One thought exercise I use: how can LLMs make impossible problems possible? In other words, how can LLMs take something that humans simply cannot do, and make it into something doable.
A friend and I were recently chatting about an example in genome sequencing. It’s incredibly difficult for humans to sequence DNA, which—to get technical—involves determining the order of nucleotides in DNA. But LLMs can translate these sequences into language problems (which are then translated into math problems, as outlined above) that become solvable. What was once intractable becomes still very, very difficult—but possible. There are a few startups working on this.
This means incredibly specific training data—more on that below.
2) Make Easy & Frustrating Problems Easy & Convenient
There are another set of problems that are actually quite easy for humans, but incredibly frustrating and time-intensive.
I’ve harped on and on about resale over the years, and how no one has quite cracked supply on resale, despite tremendous demand for secondhand products. Simply put, no one wants to catalog their items and go back-and-forth with potential buyers. Doing so is easy, sure, but a total pain in the ass.
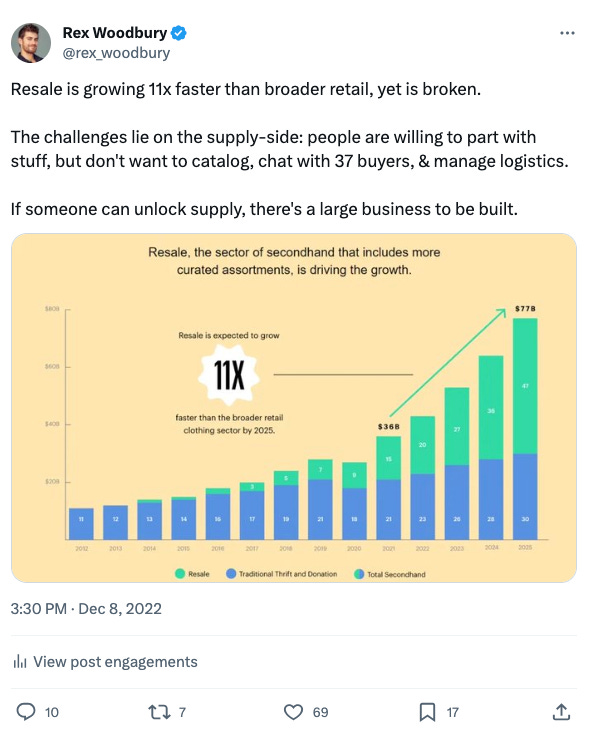
The good news: this is exactly what LLMs are good at. Can language models abstract away the friction of matching supply and demand by mimicking those 37 back-and-forth messages? This will hopefully be true in categories like resale, as well as in other categories that involve tremendous human input and back-and-forth (for instance, services marketplaces like finding a plumber or tutor).
3) Vertical AI ➡️ Vertical SaaS
Vertical SaaS is an elegant business model and a reliable playbook: start by identifying a salient painpoint for a specific user in a specific market; solve that painpoint, then expand the product suite to encompass other painpoints; eventually become the source of truth and one-stop-shop through which that person runs their day-to-day; layer on payments to own the flow of dollars, and take a cut.
We’ve seen this work across industries: ServiceTitan for home services; Wrapbook for film and TV production; Shopmonkey for auto repair; Toast for restaurants; Boulevard for salons and spas. There are countless other examples.
Vertical AI is similar: become incredibly focused at serving one specific customer in one specific industry, and use that specialization to deliver a 10x product. In AI, though, this means training a model on specific data that creates a feedback loop that leads to product improvement.

Genome sequencing, as noted above, could be an example. As could products tailored to lawyers (e.g., Harvey), to doctors (e.g., Deepscribe), to teachers (e.g., Class Companion), or to architects (e.g., SketchPro).
Focus is key—verticalization for LLMs drives better data, which in turn drives better product and better business performance.
4) More, Faster
One widespread framework for AI is the “copilot” thesis. Everyone gets an AI copilot that supercharges their knowledge and creativity. I wrote about this in The AI State of the Union last spring.
I like this thesis in that it’s the probable near-term outcome. Before AI outright replaces humans, it will supercharge them. GitHub Copilot—which GitHub claims helps developers complete 46% of code—is the first AI copilot product to publicly announce that it’s crossed the $100M ARR mark.
Or consider a study out of Harvard Business School last week on how LLMs amplify consultants’ performance. In the HBS experiment, consultants randomly assigned access to GPT-4 completed 12.2% more tasks on average and worked 25.1% faster. Quality improved by 40%.
Does this mean we’ll work less? Doubtful:

Human labor used to be about subsistence—farming, to get enough to eat. Now work has moved up Maslow’s Hierarchy to fill our needs for community and self-actualization. One example: higher-income workers are actually working more hours than lower-income workers.
But AI can supercharge our productivity, thereby driving overall GDP growth. I think of AI copilot tools as allowing us to do more, faster.
And these tools should be priced in accordance with their value. A junior McKinsey consultant runs clients $67,500 per week on average. If an AI tool improves that consultant’s output by ~25%, should it be priced at $17K per week? It’ll be interesting to see how these tools price; old world per-seat SaaS pricing might need to be revisited.
Final Thoughts
LLMs have improved exponentially in recent years—and they’ll continue to grow in size and capability. We’re still early, and we’re only beginning to see what applications emerge from the technology. I’m sure there are ideas and markets and opportunities I’ve missed here. If you’re building an LLM application, I’d love to hear about it.
Sources & Additional Reading
My two favorite LLM explainers, that go into much more depth, are this explainer from Ars Technica (Timothy B. Lee and Sean Trott) and this explainer from the FT (Madhumita Murgia)—I highly recommend them both
I like how Sarah Tavel frames pricing for AI tools as “work done” vs. per seat pricing as we’ve seen in traditional SaaS
Thanks for reading! Subscribe here to receive Digital Native in your inbox each week: