
Pixel Perfect: How AI Unlocks Creativity
Image Models, 3D Content, and the Startup vs. Incumbent Battle

Weekly writing about how technology shapes humanity and vice versa. If you haven’t subscribed, join 50,000+ weekly readers by subscribing here:
Pixel Perfect: How AI Unlocks Creativity
One of my favorite things on the internet this week was seeing NFL stadiums reimagined with AI. You had the Tampa Bay Buccaneers stadium refashioned as an enormous pirate ship.

You had the Philadelphia Eagles stadium reimagined as a massive eagle’s nest.

Other concepts included the Saints stadium as a giant cathedral, the Jets stadium as an aircraft carrier, and the Vikings stadium situated in a barren tundra.

These images were clearly generated using Midjourney, which has become recognizable for its distinctive style.
Midjourney is one of the biggest startup success stories in recent years, but it flies under the radar. This is largely because Midjourney has eschewed venture funding, instead charting its own path. Available only via Discord, Midjourney offers its product to users via tiered subscription plans, with the cheapest at $10 / month. (In March, Midjourney got rid of its free tier.)
Since its summer 2022 launch, Midjourney’s community has swelled to 16.4M members, making it by far the largest server on Discord. The next-largest servers hover around 1M members. Revenue is reportedly north of $200M and the company is profitable—all with just 11 full-time employees (!).
In recent months, Midjourney has added new commands like “/blend,” which allow users to upload multiple images and blend them together. Since it’s Halloween week, here’s an image of me blended with an image of Ken, this year’s #1 costume:

Or here’s me blended with a zombie:

Under the hood, Midjourney works by using a diffusion model. Diffusion models gradually add “noise” to an image, then reverse that process to create wholly new images similar to the original ones, but slightly different. This allows for many variations. (More about how diffusion works in this breakdown.) Midjourney was trained using an enormous scrape of effectively the entire internet.
What’s so cool about Midjourney—and generative text-to-image models in general—is that they create remixable ideas. Nearly anything you dream up can be quickly produced in a slick, stylish output. I like how Midjourney’s David Holz put it in one of his first interviews:
We don’t think it’s really about art or making deepfakes, but—how do we expand the imaginative powers of the human species? And what does that mean? What does it mean when computers are better at visual imagination than 99% of humans? That doesn’t mean we will stop imagining. Cars are faster than humans, but that doesn’t mean we stopped walking. When we’re moving huge amounts of stuff over huge distances, we need engines, whether that’s airplanes or boats or cars. And we see this technology as an engine for the imagination. So it’s a very positive and humanistic thing.
An engine for the imagination.
I’ve written before about the Creator Triad, a framework for thinking through how technology enables creativity. The Triad has three points: tooling, distribution, and monetization. In other words: how people make stuff, how they get that stuff in front of other people, and how they get paid for it. Examples of startups in each: Canva for tooling; YouTube for distribution; Patreon for monetization. Some companies, like TikTok or Roblox, hit on all three.
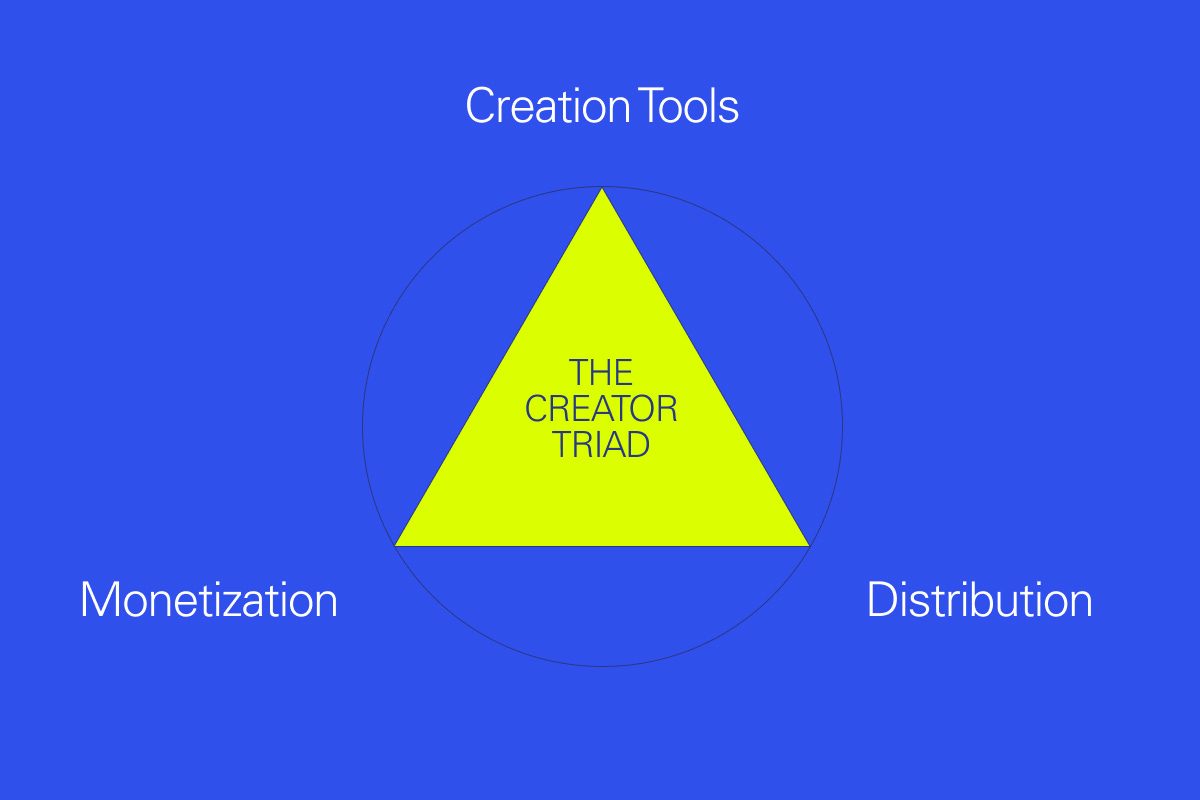
When I think of the internet, I think of a distribution revolution—new pipes through which information and content could travel. Mobile then supercharged distribution; we all got supercomputers in our pockets.
When I think of generative AI, I think of a production revolution.
The biggest opportunities in internet and mobile were in distribution: Google disseminating information, for instance, or Facebook and Instagram and YouTube disseminating content. The biggest opportunities in generative AI, in my mind, lie in creative tools. There will still be new networks for distribution, yes, but I’m excited about products that will reinvent how we make stuff—how we unleash creativity. ChatGPT and Midjourney are early examples here on the language model and image model fronts.
This week’s Digital Native dives deeper into what’s happening in creative tooling, then touches on distribution and monetization. We’ll end by looking at some ripple effects of generative AI, user-generated generated content, and the forthcoming wave of 3D.
Creative Tooling
Distribution & Monetization
Ripple Effects
Let’s dive in 👇
Creative Tooling
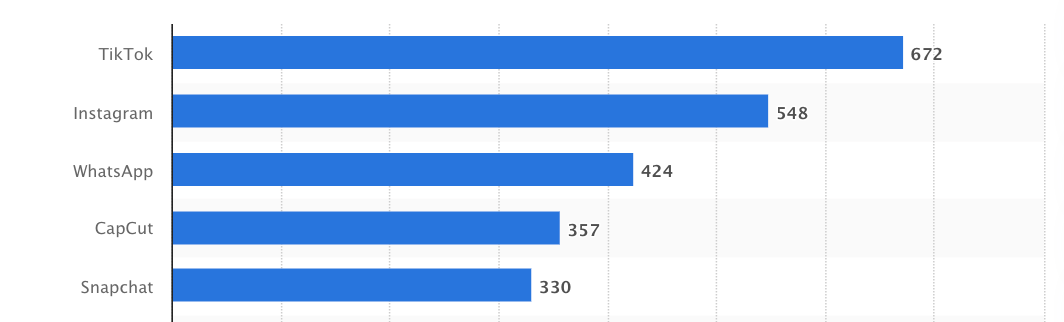
CapCut is one of the most underrated apps out there. The editing app, owned by TikTok-parent Bytedance, was the 4th-most-downloaded app in the world last year: its 357M downloads wedged it between WhatsApp (424M) and Snapchat (330M). My guess is it’s the only app in the top 5 that’s not an intergenerational household name. Your average Boomer has definitely not heard of CapCut.
Yet CapCut is incredibly popular with Gen Z. The app reportedly hit 200M monthly active users earlier this year, about one-fifth of TikTok’s ~1B monthly active users. Given that CapCut is mostly used to edit videos for TikTok, this implies that at least 1 in 5 TikTok users also creates content for the app; the figure is likely much higher, and I’ve heard estimates as high as 60%.
This is a far cry from YouTube, which has a creation rate closer to 1 in ~1,000. (I haven’t seen definitive data on this; if anyone has, I’d love to take a look.) Comparing TikTok and YouTube captures the years-long evolution toward more accessible creation tools. Here’s one of the first-ever graphics in Digital Native, from over three years ago:

Over time, creative tools have removed the need for expensive equipment and specialized knowledge. Best Picture-winning films like Parasite were edited on Apple’s Final Cut Pro X, software that costs just $299. Any artist running software from Native Instruments can recreate the sound of a $100,000 Steinway piano with incredible fidelity. Anyone can make stuff—really, really good stuff.
Generative AI tools like Midjourney and DALL-E (OpenAI’s text-to-image model, a portmanteau of Pixar’s WALL-E and the artist Salvador Dalí) take things a step further. All people need to do is input a text prompt or upload images; then anyone can generate gorgeous works.
This opens new floodgates of production. Last month’s piece The Hyper-Personalization of Everything made the analogy to the Industrial Revolution: what the Industrial Revolution was to physical production, the AI Revolution is to digital production. Mass digital production at anyone’s fingertips, cheap and easy.

Where are the startup opportunities here?
The first-movers have been social apps that play to people’s Vanity. (Remember the Seven Deadly Sins Framework for consumer technology.) The first big one was Lensa last December, which let us create AI-generated images of ourselves—each image just a liiiiittle more attractive than we are in real life.

Naturally, everyone posted their Lensa avatars on Instagram and TikTok, driving viral growth. But that frenzy was short-lived: like most social apps, Lensa faded as quickly as it rose.

A few weeks ago, we had a new Lensa—EPIK, the app behind the viral “yearbook photo” trend. The trend—using a similar concept to Lensa—swept the internet for a few days before also fading away.

Few creations so far have stuck; Midjourney is a clear outlier. But there are new venture-backed companies enabling creativity with generative AI.
Can of Soup is a social app that lets you quickly spin up images of you and your friends, using whatever’s in your imagination. You can take a prompt like “@rexwoodbury as Taylor Swift on the cover of 1989 (Taylor’s Version)” and within seconds, get a pretty cool output:

Many Can of Soup creations involve two or more people and add in pop culture references—Rihanna’s Super Bowl outfit, Pixar style, Dragon Ball Z aesthetic, and so on. It’s like productizing Midjourney’s “blend” feature in its own standalone app, then adding a social graph.
This is interesting because it captures remix culture. TikTok is built on remixes—combining various components of sounds and memes and images into an easily-digestible, highly-entertaining whole. AI, when used smartly, can accomplish the same.
The challenge for AI social products—and there are have been many popping up—will be demonstrating the product velocity to maintain relevance and public attention (which, translated into metrics, means engagement and retention). The rest will go the way of Lensa and EPIK—an outcome, by the way, which isn’t to be scoffed at. At its peak, Lensa was raking in more than $2M a day (!); its developers profited handsomely. But in order to build a sustainable, venture-scale business, AI consumer applications will need to keep innovating and adding new features.
The wave of generative AI is also beginning to collide with the wave of 3D content. 3D content is the natural next step in the migration toward more immersive content formats:

August’s The Future of Technology Looks a Lot Like Pixar dug into the creation of the Alliance for OpenUSD. Apple, in preparation for its Vision Pro launch next year, announced that it’s partnering with Pixar, Nvidia, Adobe, and Autodesk to create a new alliance that will “drive the standardization, development, evolution, and growth” of Pixar’s Universal Scene Description (USD) technology. In other words, to expand the technology that Pixar uses to build 3D content.
(USD is open-source software that lets developers move their work across various 3D creation tools, unlocking use cases ranging from animation—where it began—to visual effects to gaming. Creating 3D content involves a lot of intricacies: modeling, shading, lighting, rendering. It also involves a lot of data, but that data is difficult to port across applications. The newly-formed alliance effectively solves this problem, creating a shared language around packaging, assembling, and editing 3D data.)
There are new creative tools built to help people make stuff in 3D. Spline, for instance, is 3D design software with real-time collaboration in the browser. It’s a good place to start for beginners—if you’re building a 3D website, Spline is fairly intuitive to learn.

One of the best products I’ve used recently is Bezi (formerly called Bezel), a Seed-stage startup built by former Oculus developers. Bezi is for 3D design and prototyping; here’s me playing around in it:

The sign-up flow alludes to the broad use cases for 3D—from animation to gaming, education to graphic design, AR / VR to fashion. Soon enough, we’ll all be making 3D creations—often without knowing a line of code.
Generative AI will seep more and more deeply into 3D, abstracting away complexities. The end state here: tools that allow us to create robust 3D worlds with simple text prompts.
Zooming out for a moment, we see innovation across every content format. Creative tools bring AI into images and videos, avatars and voices. There are dozens of startups building here, but examples include:

The key question: how can startups crack distribution and monetization?
Distribution & Monetization
People take a lot of photos. Setting aside a COVID-related 2020 and 2021 dip (fewer experiences to take photos of), photos have been on an upward trend:

We’re closing in on almost two trillion photos a year. According to the team at Contrary, which has a great research report on Midjourney, the average person has around 2,000 photos on their smartphone—iOS users have around 2,400, and Android users have around 1,900 (fewer friends to take photos with given their green texts 😕).
Glancing at my phone, my count is significantly higher.

Every day, people share 14.1B images on WhatsApp, Snapchat, Facebook, and Instagram. That’s up 3x since 2013.
The question is—how much of the internet’s content will be AI-generated? Some experts predict 90% of online content will be synthetically-created by 2026. Other predictions come in even higher: the Copenhagen Institute of Future Studies’s Timothy Schoup expects closer to 99.9% of content to be generated by AI by the 2025-2030 timeframe. NVIDIA’s Jensen Huang predicts that every pixel will soon not be rendered, but generated.
This leads into distribution: how will content get in front of people, especially when there’s so much more of it? And on the monetization front, how will people get paid for what they make?
I see two key business models developing:
Freemium, Tiered, & Per-Seat Pricing: This is the likely business model for most creative tools—Midjourney, Runway, Bezi, and so on.
Ad-Based Networks: Digital ads may be the most elegant business model ever created. (Search in particular probably takes the cake.) AI content will proliferate on networks, which will monetize through ads. Those ads themselves will likely be generated: generative ads allow for even more specific targeting, and can be much more economical for brands. Midjourney is already disrupting stock image companies like Shutterstock (which hosts over 1B images), and vertical-specific players like Treat power creative for categories like CPG.
There may also be social platforms purpose-built for AI content. These will have built-in creative tooling alongside distribution. Can of Soup above is an example of this.
I also see an opportunity for an “AI Pinterest.” Pinterest is proving surprisingly popular with Gen Zs: in its earnings report this week, the company reported its highest-ever monthly active users (482M) and said that Gen Z users are the fastest-growing, highest-engagement segment. Yet U.S. users are in decline, down 13M since Q1 2021; Europe is down 8M. A rise in “Rest of World” users (+24M) has offset those declines.
AI, meanwhile, offers a natural next step for Pinterest—or a pioneering startup. Midjourney’s Showcase feature is somewhat like AI Pinterest—a place to get inspiration from other people’s prompts and creations. You can envision a more intentional and social destination built around verticals: interior design; architecture; gaming concept art. I hope someone in the New Products team at Pinterest is paying attention.

Midjourney launched on Discord because the social component was so important. As Holz put it:
“A lot of people ask us, why don’t you just make an iOS app that makes you a picture? But people want to make things together, and if you do that on iOS, you have to make your own social network. And that’s pretty hard. So if you want your own social experience, Discord is really great.”
This gets to an interesting question: will startups or incumbents win?
Incumbents, of course, have built-in distribution. And they haven’t been caught flat-footed. Figma and Canva both have robust AI products. Adobe Firefly—billed as “Generative AI for everyone”—seems to be a rocket ship. On September 13th, Adobe announced that users had generated over two billion images using Firefly. Less than a month later, on October 10th, Adobe announced Firefly had hit the three billion mark.
YouTube, meanwhile, unveiled AI-powered tools for video backgrounds and dubbing. YouTube had hoped to unveil an AI music tool as well—a tool that would let users perform using the voices of major artists. The only problem was that YouTube couldn’t come to an agreement with the major music labels. (Should AI music be treated as sampling, as UGC? How much should artists and labels get paid? There are many questions to be answered.) But YouTube is often at the vanguard of music innovation—its landmark agreements with labels back in the late 2000s came months before Google agreed to buy YouTube—and this sort of creative tool is likely coming soon.
The point is: generative AI is a new revolution, but it’s coming at a time when Big Tech has never been bigger and when incumbents have never been more aware of potential disruption.
That doesn’t mean there aren’t opportunities. Chances are, in a few years there will be a new household name in creative tooling, and likely a new name in distribution and monetization as well. (Maybe it’s all one company.) ChatGPT already got there—fast—but there are probably a few more nascent startups that will also break through.
Revolutions like this create openings for startups, but founders will need to be extra savvy, nimble, and fast-moving to seize the moment.
Final Thoughts: Ripple Effects
It’s interesting and important to contemplate the ripple effects of AI dominating creativity. Two examples:
Last week The Atlantic ran an article with the catchy title, AI Has a Hotness Problem. The argument was that AI-generated faces tend to be…really attractive. To test it out, I input a relatively innocuous prompt into Midjourney: “Show me a male human face, staring into the camera at sunset, photorealistic, 4K.”
Sure enough, this is definitely not your average human face.

Why does this happen? One argument is that images used to train image models were largely scraped from the internet. Internet photos include many, many images of highly-photographed celebrities and other “professional hot people”—as well as our own user-generated, yet heavily-Facetuned photos. Image models may have learned that your average person has pearly white teeth, high cheekbones, and a chiseled jaw.
A second example: many AI-generated images of watches show the time as 10:10. Why? Most watch advertisements show the watch’s hands at the aesthetically-pleasing 10:10 configuration. These ads trained the model, and voila. The input is biased by the training data.

It’s important to contemplate the biases that flow into AI—and what it means when AI creations are unrealistic or non-average. Having access to every other person on Earth through social media shaped the last 15 years with its aftershocks; being able to generate anything with AI may shape the next 15.
We’re only in the early innings here, and things are moving fast. More and more of us are learning to make stuff—AI stuff, 3D stuff—with increasingly powerful tools. There are large opportunities to seize, given the pace with which things are changing, but there also large social shifts unfolding that we won’t learn to appreciate for years to come.
Sources & Additional Reading
How Diffusion Models Work | Stable Diffusion
Thanks for reading! Subscribe here to receive Digital Native in your inbox each week: